Aalto’s Mobile Cloud Computing Group is Collaborating with CMU in Wearable Cognitive Assistance
Cognitive assistance is a promising application area for wearable computing. In the context of mechanical assembly, the user is guided through the step-by-step sequence of a task workflow. The end point of each step (e.g. a particular screw mounted flush into a workpiece) needs to be defined precisely, while being tolerant of alternative paths to reaching that end point (e.g. hand-tightening versus using a screwdriver). Authoring a wearable cognitive assistance application is time-consuming and often requires collaboration between a task expert and a software developer with highly specialized skills in computer vision. Developing a single application typically takes several person-months of effort.
Aalto’s mc2 – Mobile Cloud Computing group is collaborating with Prof. Mahadev Satyanarayanan‘s group at Carnegie Mellon University (CMU) to create more effective tools. The CMU group has developed Gabriel, an edge computing platform for cognitive assistance, and has experience from several applications built on top of it. The mc2 group has complementary expertise in automatic extraction of workflows from first-person videos.
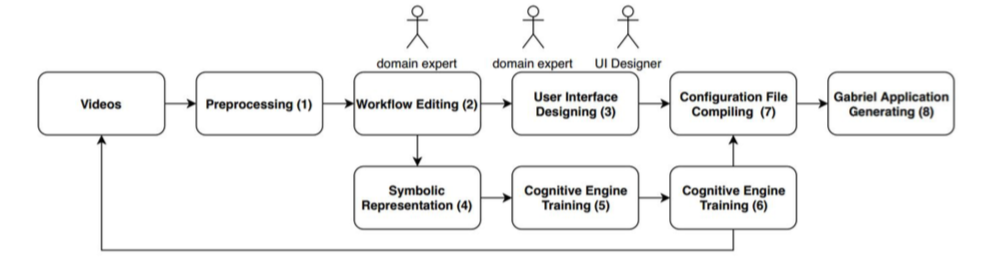
Truong-An Pham from the mc2 group made a two-month research visit to CMU in Autumn 2018. Among the results of the collaboration is a three-stage toolchain for generating cognitive assistance applications for mechanical assembly:
- A workflow is extracted automatically from videos of experts performing a task. Since the extraction process is imperfect, a workflow editing tool is provided for making corrections.
- The vision-based object detectors needed for the task are created. Accurately detecting the presence and location of relevant objects in a video frame is the key to recognizing progress on a task. The work is done by a task expert, who creates training data for deep neural networks using a web-based tool.
- The extracted workflow and the object detectors are linked to generate task-specific executable code for the task-independent Gabriel platform. Cognitive assistants are represented as finite state machines (FSMs), in which each state represents a working step or an error case. Changes detected in the input video stream trigger state transitions. Libraries are provided to create, persist and debug the FSMs.
The next major step in the project is a user study conducted at Aalto University in May 2019.
Overview of the toolchain